Rust Hacking - Scalar Type (Part 1)
文章目录
最近遇到很多 Rust 的二进制程序,在分析中遇到了比较多的问题,所以本系列打算从基础开始,总结一些分析 Rust 二进制的基本步骤以及相关的技巧。
Scalar Type
首先我们看看在 Rust 中 Scalar Type 在编译之后会如何在内存中表示。我们新建一个示例项目:
| |
打开 main.rs 写入如下代码:
| |
在这个例子中,我们测试了 Rust 中的基本 Scalar Type, 编译执行,可以得到预期结果:
| |
Analysis Scalar Type (IDA)
在 IDA Free 中加载编译后的二进制,待分析完成后,我们可以看到停在如下图所示位置:
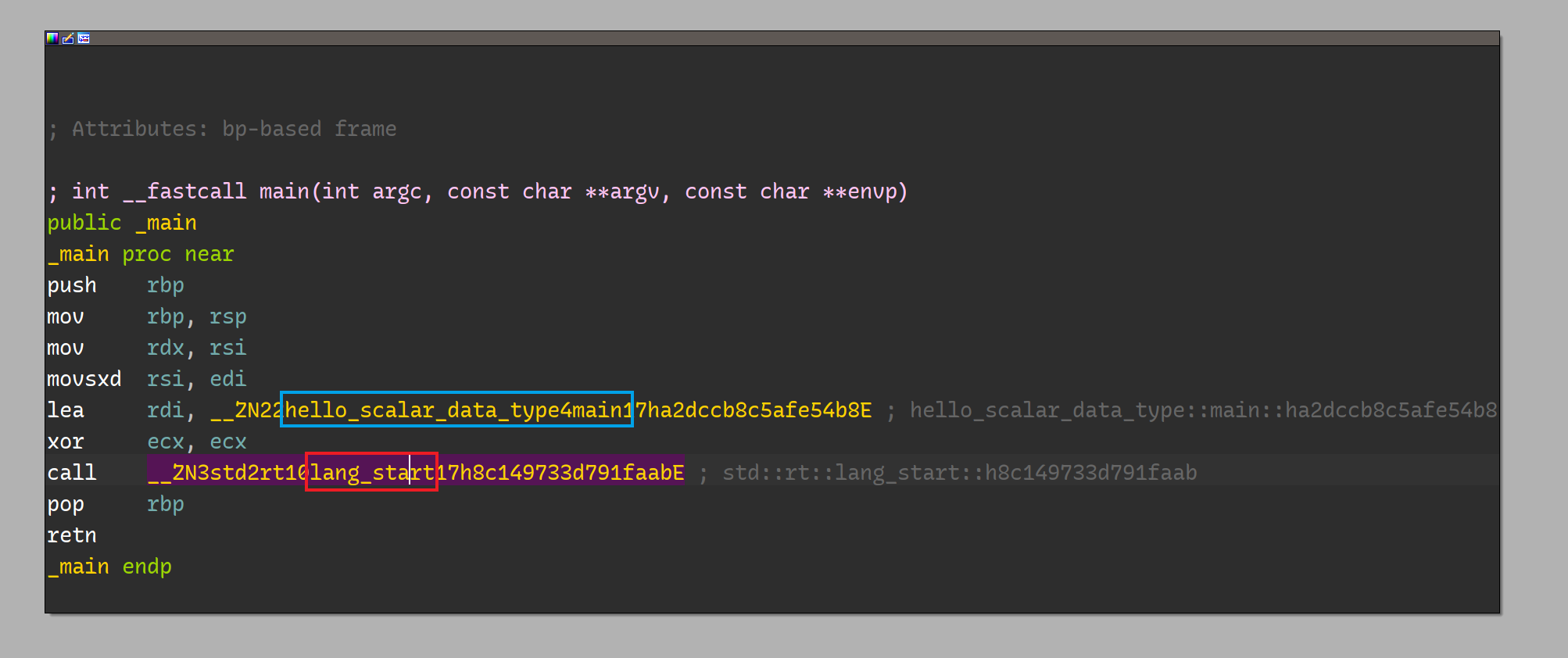
与 C-like 语言不同,项目(hello_scalar_data_type) 的 main 函数地址作为参数传递给 Rust 的 Runtime 入口点 lang_start. 并且,查看 IDA 左侧的符号列表
可看到几乎所有符号(除了引用的外部库函数符号)都经过 mangling 处理。双击 hello_scalar_data_type 进入 user-main.
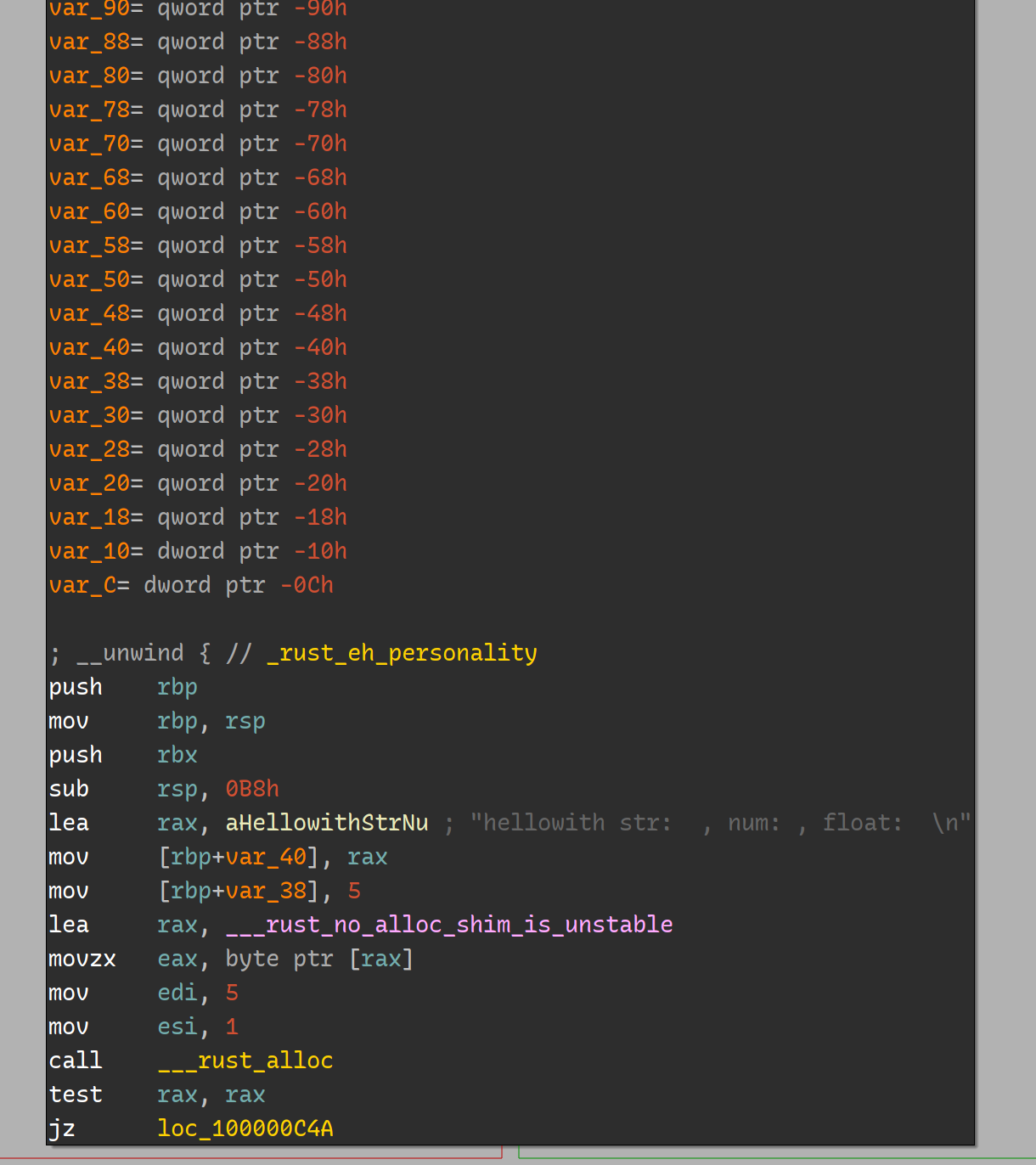
查看 aHellowithStrNu 处字符串字面量:

可以看到与 C-like 的字符串不同,Rust 中所有字符串字面量统一保存在 rodata 节中,字符串无 ‘\0’ 结尾。 整个字符串池会以 ’\0’ 结尾。 而字符串 “world" 则是动态分配到内存中:

接下来的逻辑初始化相关变量,最后调用 print 输出到 stdout.
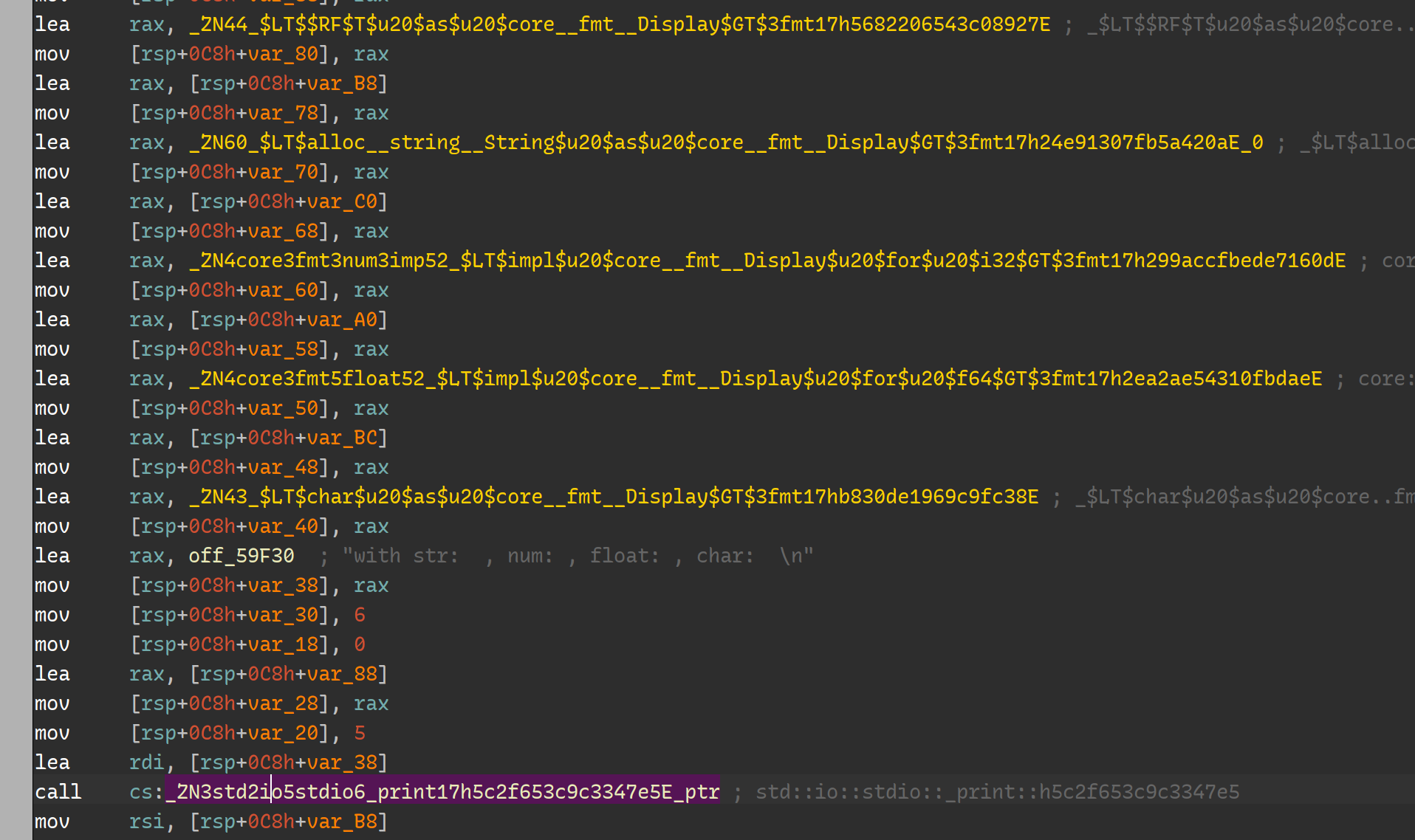 最后将字符串 ”world" 的内存释放,然后进程结束。
最后将字符串 ”world" 的内存释放,然后进程结束。
Debugging And Hacking (GDB)
接下来在 GDB 中验证上述分析过程,并尝试 hacking 相关内存。
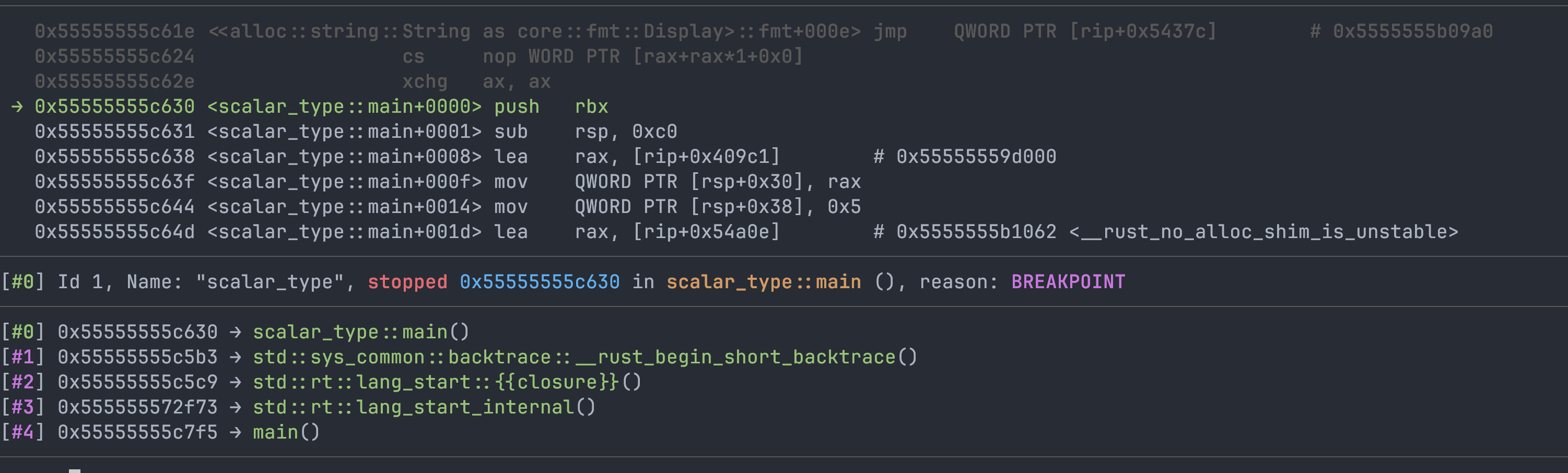 GDB 下断到
GDB 下断到 scalar_type::main 上, start 断下来后看到堆栈确实是由 Runtime 中的 lang_start 走过来的。
接下来看看字符串池:
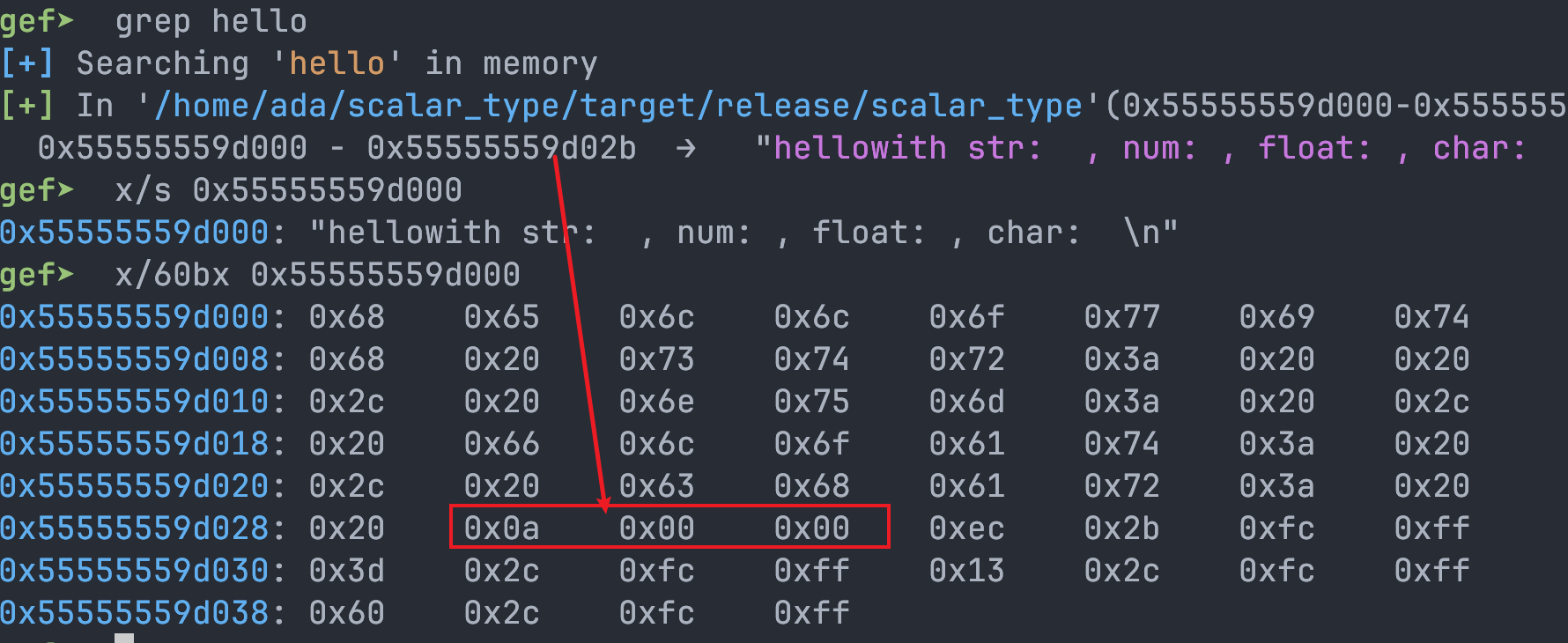 同样,与静态分析的结果一致。
同样,与静态分析的结果一致。
Hacking String Slice
尝试在此字符串字面量后接上 “Hacked"
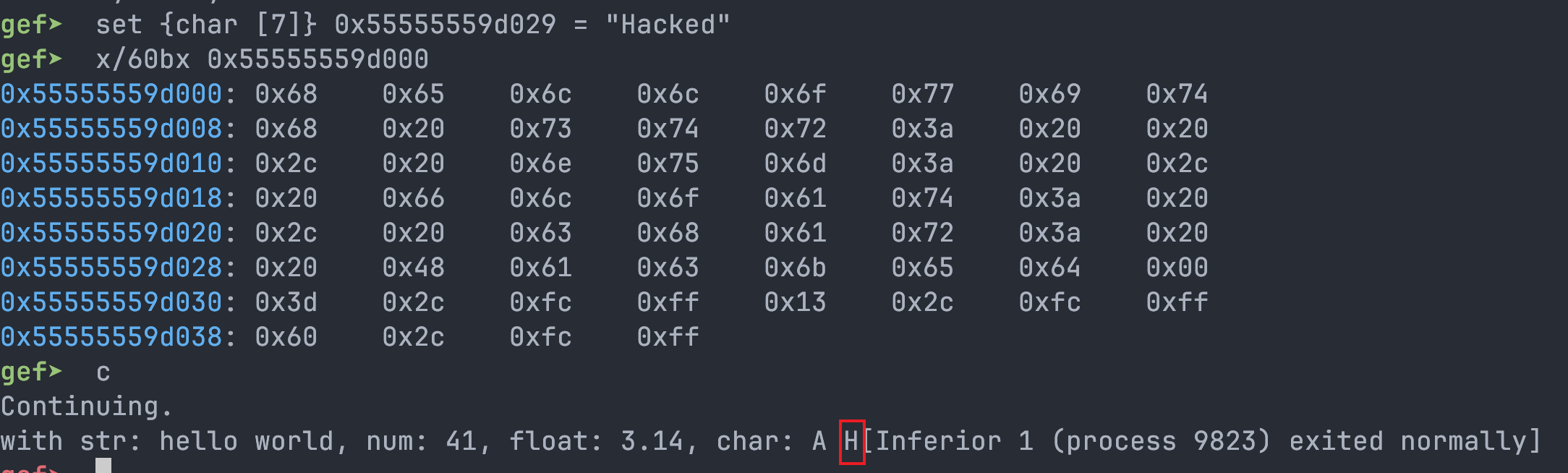
成功写入了内存,但之后字符 ’H’ 输出了。首先,只有字符 ’H’ 输出是因为替换的原本字符是换行符。后续的字符串未输出是因为 Rust 中字符串字面量是通过 &str 类型使用的(胖指针):
| |
在二进制文件中也可以验证这一点:
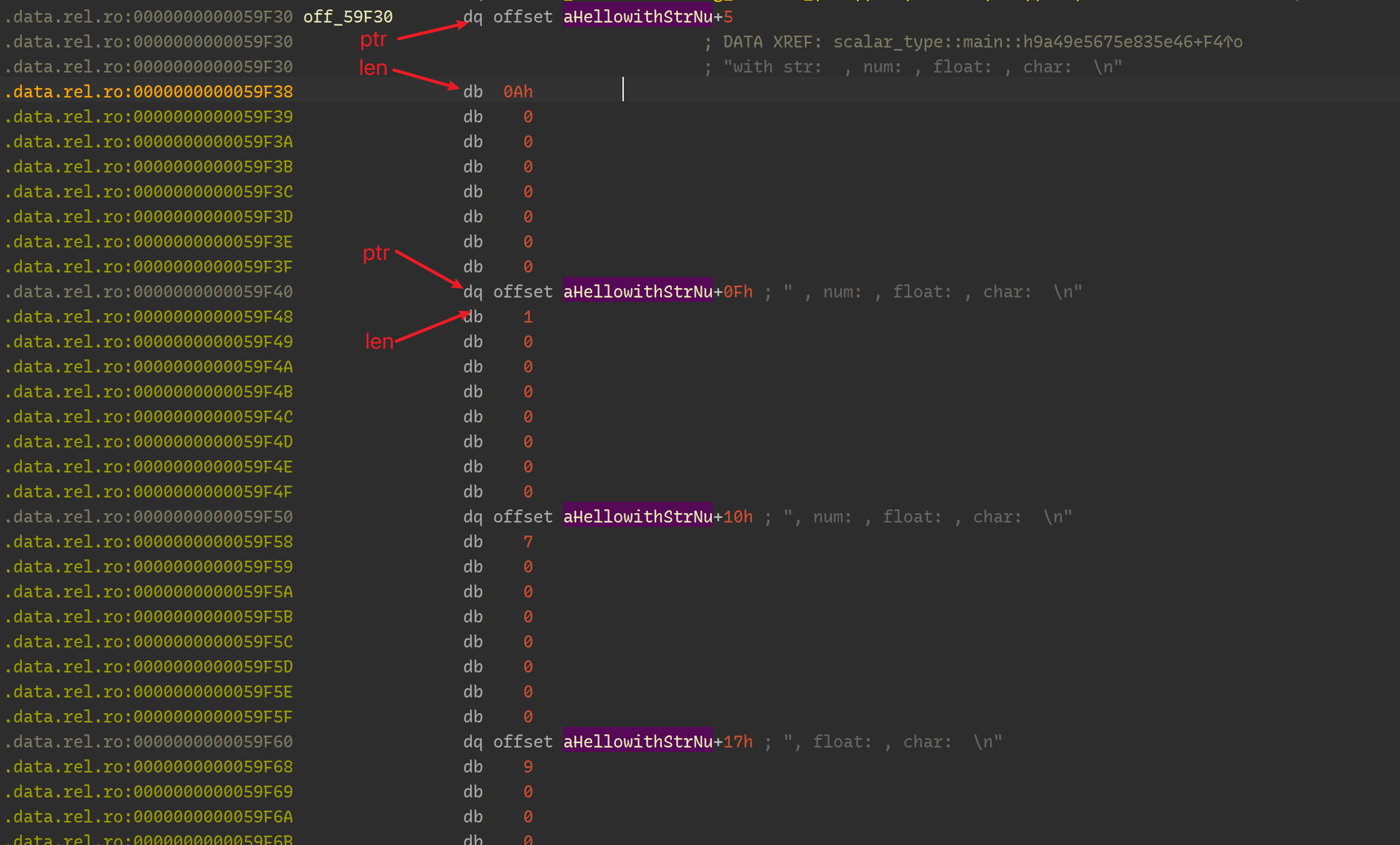
另外,从此处也可以得出, println! 中引用的字符串会由于 format specification 而分割成不同的部分:

看看这些不同的部分在何时进行处理的,在 len 地址处下内存访问断点, continue 程序,会断在如下逻辑处:
 在判断 len 是否为 0,此处跳转不会发生,继续单步到
在判断 len 是否为 0,此处跳转不会发生,继续单步到 call 处:

根据 rax 处指令看起来像是内存分配,首先搜索一下内存当前访问的字符串,仅有一处命中(二进制文件自身内存):
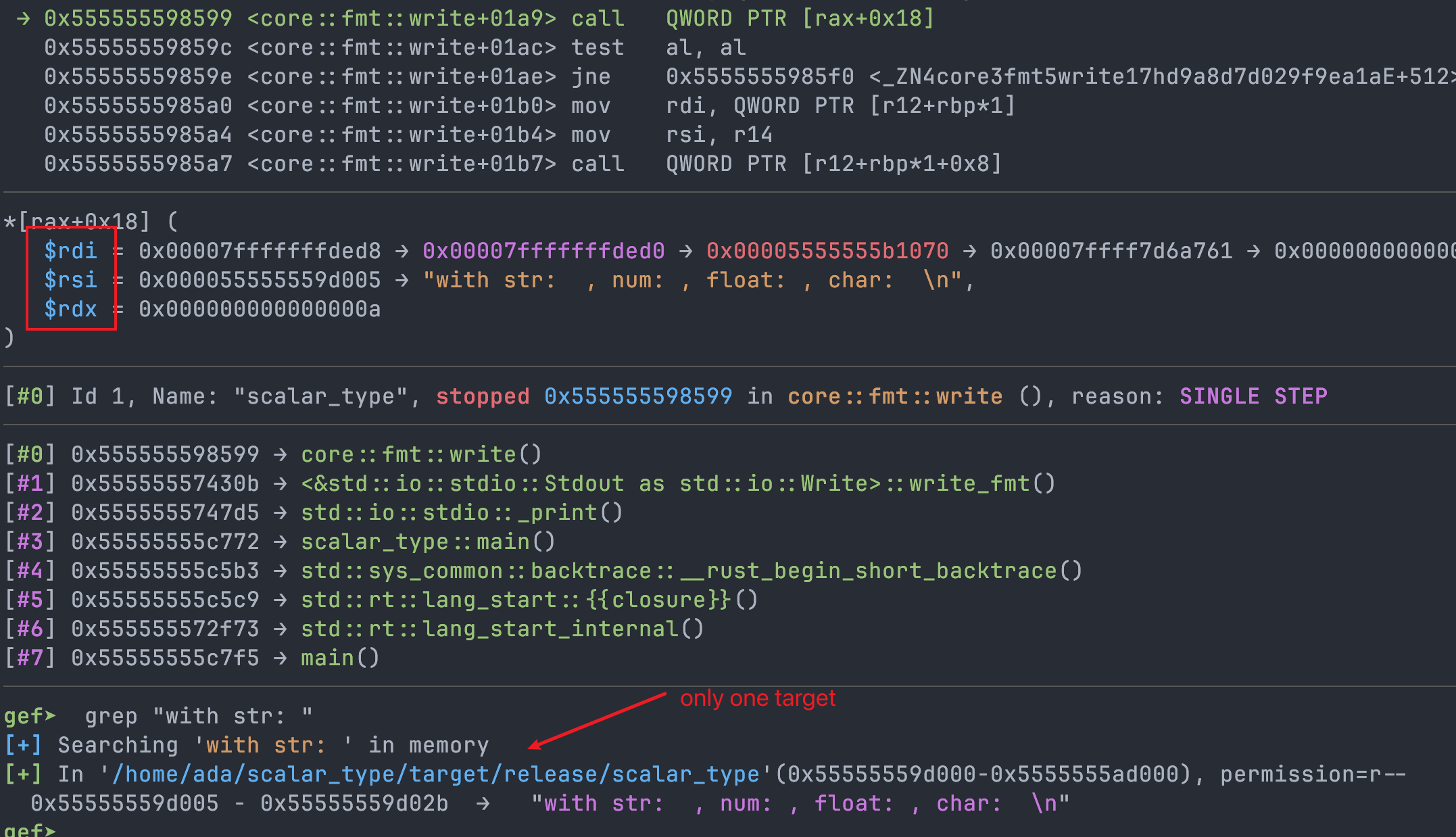
单步步过此 call 之后,再次搜索,发现在 heap 上多了一处命中,即验证猜测,此处为字符串在 heap 上分配空间,待 format specification 被替换。

后续其他字符串部分也会同样在 heap 上分配,并填入相应的变量。所以,此处 Hacking 还需要更改 str slice 的 len 字段:
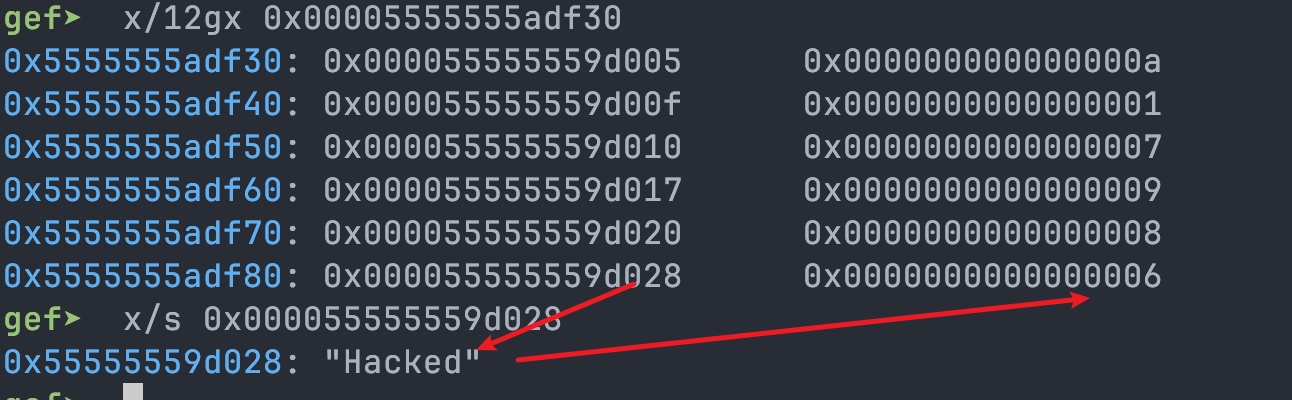 更新之后即可看到 Hacked 成功:
更新之后即可看到 Hacked 成功:

总结
- Rust 二进制程序编译后由于自带一个小的 Runtime, 编译后的二进制大小一般较大。
- 符号名经过 mangling 处理,增加了静态分析的难度。
- Scalar Type 的内存布局符合预期,值得注意的是,所有字符串字面量统一存储在 rodata 节中,只有整个字面量以 ’\0’ 结尾, 由于通过切片引用,所以各个字符串之间没有额外的分隔符。
文章作者 curtainp
上次更新 2024-05-28 (8ae03f7)